Movie release live-calendar using CloudFlare Workers, KV, and Terraform

Why
Before the world of attention economy the internet was built on a subscription model of information. You subscribed to a topic, rather than have "related promoted" topics pushed to you. Therefore, as we reach the peak of algo-driven TikTok platforms I thought it'd be the perfect time to remind users of when we could simply subscribe to information, and enjoy it.
What
To start our revolution small, let's look at the fact that The Movie Database (TMDB) serves a neat list of upcoming films. As a strict keeper of a calendar I know there's a niche ability still supported by most to subscribe to a URL that serves a live calendar. I figured therefore it shoudl be easy enough to list upcoming films in my calendar.
The rough steps involved will be to poll TMDB and ask it for any films being released over the next few weeks, rewrite that into the iCal format and serve it via an API. Extra credit for a nice site, some kind of hosting format that doesn't cost too much, and the ability to let user's control the information they receive.
TLDR; The end result can be found here. You apply the relevant filters, then go to your calendar app of choice (GMail) and add the live-calendar. If you want to be helpful set it's sync to either daily or weekly, given the data isn't going to update any faster than that (really wish iCal supported a way of telling clients to default this).
How - High level
CloudFlare has been pushing it's wider product catalogue recently so I decided to put it to the test. Some napkin-designs later I settled on the following architecture.
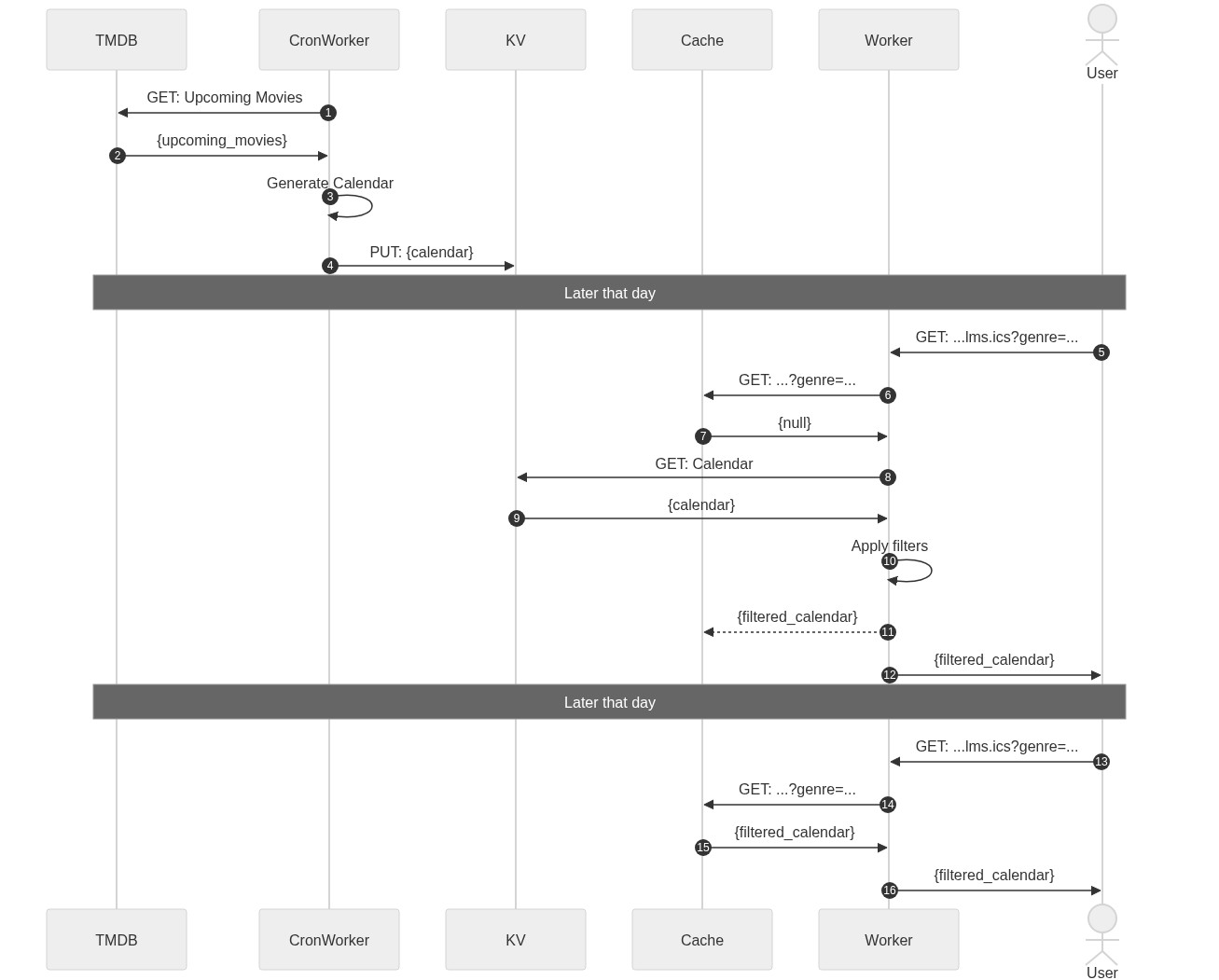
The gist is simple, every day a cron-worker goes to TMDB and pulls their "upcoming films" data-set, then puts that into CloudFlare's Key-Value store (KV) keyed by today's date (with an auto expiry).
Later that day, someone's calendar app does the daily/weekly pull of the calendar (with filters like category and region applied) whereby the worker will first ask the cache if someone else has tried that particular request yet, otherwise it'll perform the longer pull to KV of the latest data-set, apply the filters and then reply to the customer.
How - Low level
CloudFlare at the moment has a set of products that almost but don't quite fit together. They're seemingly in the early stage where they're finding their feat and moving fast, so of course breaking things.
My setup for almost anything lite these days is a VSCode project written in TypeScript, deployed locally via a set of package.json commands.
"scripts": {
"setup": "terraform init",
"start": "wrangler dev",
"plan": "terraform plan",
"deploy": "run-s deploy:*",
"deploy:build": "npm run build",
"build": "npx wrangler publish --outdir dist --dry-run",
"deploy:cloudflare": "source .env && terraform apply -auto-approve"
}Very roughly the deployment process is simply to npm run deploy which run's sequentially the tasks of building the app using CloudFlare's wrangler tool and then deploying the app via CloudFlare's Terraform provider.
For those that don't know, Terraform is a tool that allows you let's you describe the state of infrastructure in structured format. So rather than requiring you to keep track of the series of API-calls you'd need to perform to reach a desired state in CloudFlare, instead you define what you'd like and let CloudFlare's provider worry about that. It's not true Infrastructure as Code, but it's good enough.
It'd be fair to ask what the point of Terraform is for a project this small, but the simple fact is that Infrastructure as Code is a stunning way to handle the problem of maintaining a cloud's state and the alternative would have been a mess of CloudFlare API commands baked into some shell script. This instead off-loads all the work onto CloudFlare.
resource "cloudflare_worker_script" "upcoming_movies_script" {
name = "upcoming-movies"
content = file("dist/index.js")
kv_namespace_binding {
name = "UPCOMING_MOVIES"
namespace_id = cloudflare_workers_kv_namespace.my_namespace.id
}
plain_text_binding {
name = "MY_EXAMPLE_PLAIN_TEXT"
text = "foobar"
}
secret_text_binding {
name = "TMDB_API_KEY"
text = var.secret_tmdb_api_key
}
}
resource "cloudflare_worker_cron_trigger" "once_per_day" {
account_id = var.cloudflare_account_id
script_name = cloudflare_worker_script.upcoming_movies_script.name
schedules = ["0 4 * * *"]
}The above declares the script and it's secrets, along with the daily cron-job.
Slight pain-point. The CloudFlare workers act different in a few ways when running locally vs in the cloud. One major issue is how they provide the KV namespaces via global variables rather than as an object which can't really be bound locally leading to code like this:
...
export interface Env {
UPCOMING_MOVIES: KVNamespace;
}
declare global {
var UPCOMING_MOVIES: KVNamespace;
}
async function readOrUpdateFromKV<T>(key: string, generate: () => Promise<T>): Promise<T> {
if (global["UPCOMING_MOVIES"] == null) {
return await generate();
}
const possibleValue = await UPCOMING_MOVIES?.get(key);
console.log(`Fetching ["${key}"] from KV`);
...Another pain is how the workers aren't perfectly Node compatible. Instead requiring a Google and a flag to enable compatibility. For all the ways I can see wrangler trying to make it a painless developer experience this was a place I just expected them to have covered. If the server-side experience is different I'd have preferred them to containerise the local experience to match.
As for the front-end, there's really not much to it. It's a front-end that's deployed to CloudFlare workers wrangler pages publish. CloudFlare have a method for deploying both the pages and the workers with Wrangler but it's another area where the docs keep referring to multiple versions of deprecated methods which always makes me wary. All the documentation as well for these tools is web-client centric, which adds again to the "easy deploy" feel of the tool, rather than a "here's how to deploy this today, tomorrow and in ten years time" energy I look for in a platform.
Instead I rely on the more mature VSCode workspace which allows you to have both your front-end and back-end as parallel projects. Running the backend with wrangler and using Reacts builtin features to proxy requests to the wrangler port.
The ease of things like this is always defined however by how easy it is to work with once you've forgotten half of it. And the weeks later after dogfooding the project for a bit I realised I wanted to change the text slightly to be more obvious it was a film release.
I recloned the project, made the edit and redeployed. Worked fine so considering that a success.